CAPABILITIES
能力与方法 —— 跨项目复用的方法论
Eval 体系设计 · AI 工作流 · 本地多模态部署01 · Eval 方法论两套 Golden Dataset 的设计思路对比
| 语法助手(RAG 评估) | WordCraft(Agent 评估) | |
|---|---|---|
| 测试集设计 | 30 题覆盖教材内 / 教材边界 / 超纲三层,"为什么"类问题专测诚实拒绝 | 30 词按 4 类风险覆盖(多义词 / 低频义项 / fallback 来源 / 术语短语)+ 15 样本三类输入 Baseline |
| 核心指标 | 编造率 / 引用率 / 诚实率(先定义目标值,再实测) | 8 项指标定义(JSON 合法率、义项追溯率、例句自然度、认知负荷、low_confidence 有效率、单词成本等) |
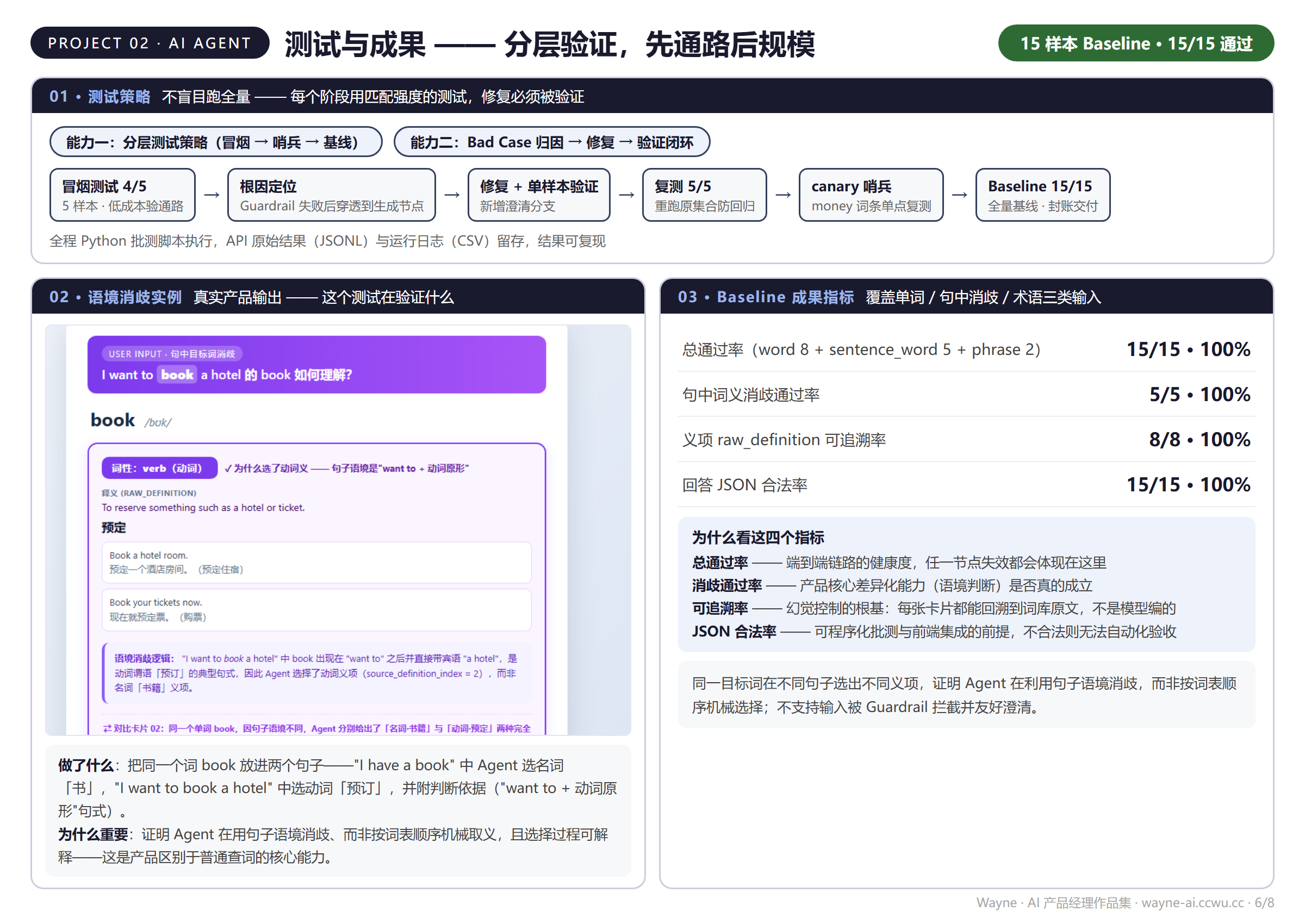
| 测试节奏 | Day 1 五题预检暴露问题 → 修复 → Day 2 全量复测 | 冒烟(5)→ 修复验证 → 复测 → canary 哨兵 → Baseline(15)→ 封账 |
| Bad Case 处理 | 逐题记录归因;教材覆盖边界与 RAG 缺陷分开归类 | 失败样本定位根因(Guardrail 穿透)→ 修复必须被验证才进下一阶段 |
| 工程化 | Python 自动化评估流程 | API 批测脚本:失败重试 / 断点续跑 / JSONL+CSV 日志 / 可复现 |
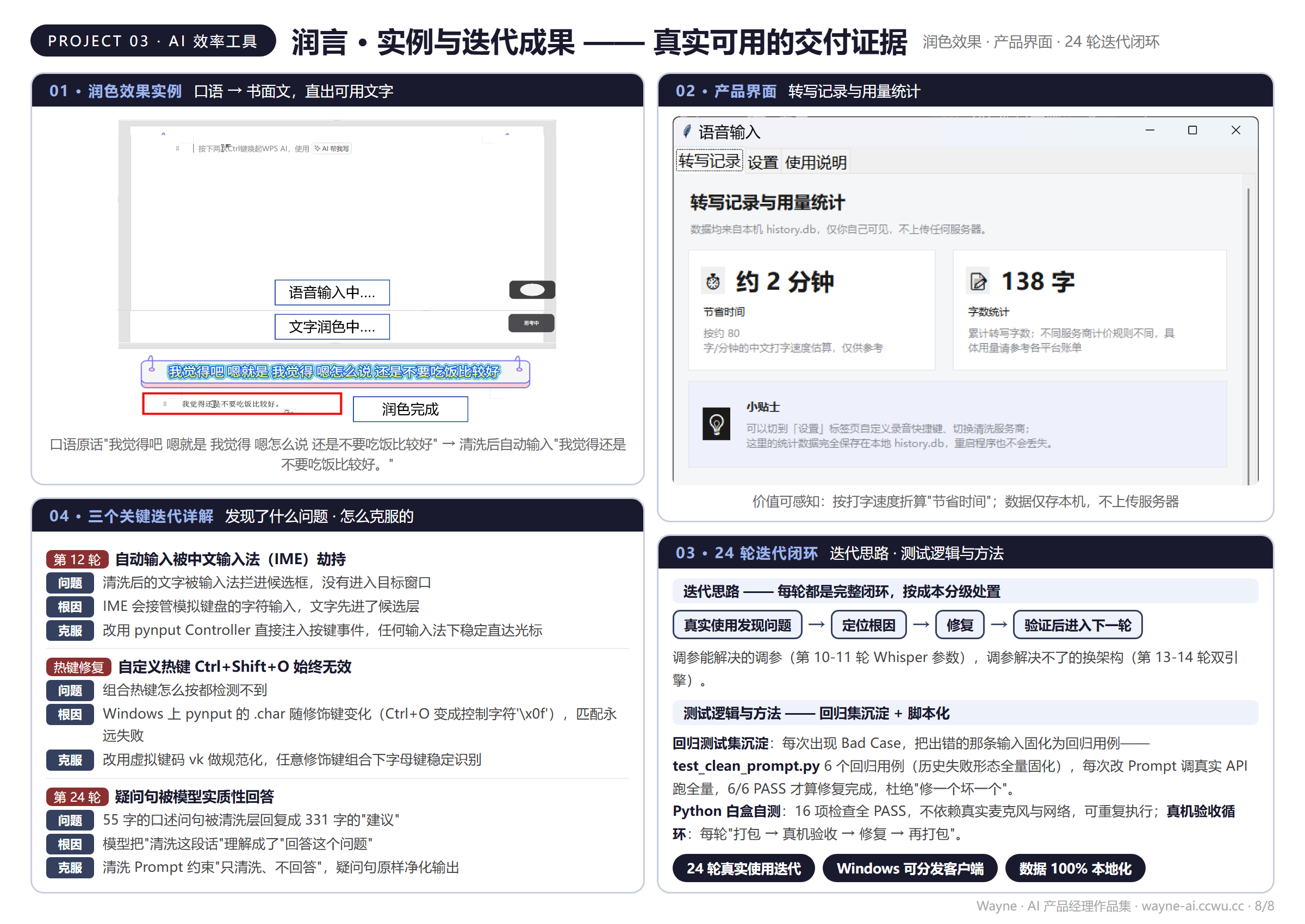
共同原则:先定义指标再跑测试、先小成本验通路再跑全量、修复必须被回归验证。润言项目同样实践了"Bad Case 输入固化为回归用例"(test_clean_prompt.py,6/6 PASS 为验收线)。
02 · AI 工作流设计个人 AI 工作流资产(代表作三件)
daily-review 复盘 Skill
基于"三问认知复盘"框架(事实可验证 / 偏差找根因 / 微行动可锚定)的每日复盘自动化,输入当天 AI 对话上下文包,输出结构化复盘。
基于"三问认知复盘"框架(事实可验证 / 偏差找根因 / 微行动可锚定)的每日复盘自动化,输入当天 AI 对话上下文包,输出结构化复盘。
context-packer 上下文打包 Skill
把跨会话的 AI 对话整理为结构化上下文包,解决"换个会话就失忆"的工作流断点。
把跨会话的 AI 对话整理为结构化上下文包,解决"换个会话就失忆"的工作流断点。
SCDR 场景路由系统提示词
按场景自动路由的个人系统提示词:识别提问类型后切换响应策略,沉淀为分层提示词体系(系统层 → 场景层 → 应用层)。
按场景自动路由的个人系统提示词:识别提问类型后切换响应策略,沉淀为分层提示词体系(系统层 → 场景层 → 应用层)。
这些资产服务于同一个目标:把重复的认知工作产品化——和三个作品集项目"把教学经验转化为产品规则"是同一种能力在工作流层的应用。
03 · 本地多模态部署基于本地 GPU 跑通的生成链路(ComfyUI)
已跑通链路:文本理解 → 语音合成(TTS)→ 数字人驱动 → 唇形同步。部署并调通的模型/工作流包括:双 TTS 引擎(含语音克隆)、LivePortrait 面部动画、Sonic 音频驱动、视频/图片对口型、RIFE 帧插值——8 个可一键导入的 ComfyUI 工作流节点配置沉淀在本地。
环境配置依赖调试显存占用优化生成效果验证语音克隆唇形同步
TTS 输出样本(本地生成,在线试听)
样本 1 · 语音合成
样本 2 · 语音合成
样本 3 · 语音合成
04 · 简历作品图速览八张项目一页图(即简历附图,点击放大)