PROJECT 01 · 教育 RAG
AI 语法学习助手 —— 把大模型约束成「只讲教材」的语法老师
教材约束型 RAG 问答产品 · 独立产品负责人 · 2026.01-2026.0301 · 项目定位解决什么人的什么问题
痛点
语法学习者用通用大模型提问时,模型直接给答案 + 自由发挥:超出教材也硬答,无法核对来源,学习者缺乏主动思考,规则难以内化。教育产品最不能容忍的就是编造。方案
教材约束型 RAG 问答:知识库限定 DK 语法教材(时态系统),教材有的带页码答,教材没有的诚实拒绝,按问题类型分流教学路径。角色与技术栈
需求定义 → 知识库与检索设计 → Prompt 工程 → Eval 评测,全链路独立完成。Dify ChatflowRAG 知识库混合检索Prompt 工程Eval 评测
02 · 产品工作流真实 Dify Chatflow 编排(实拍,点击放大)
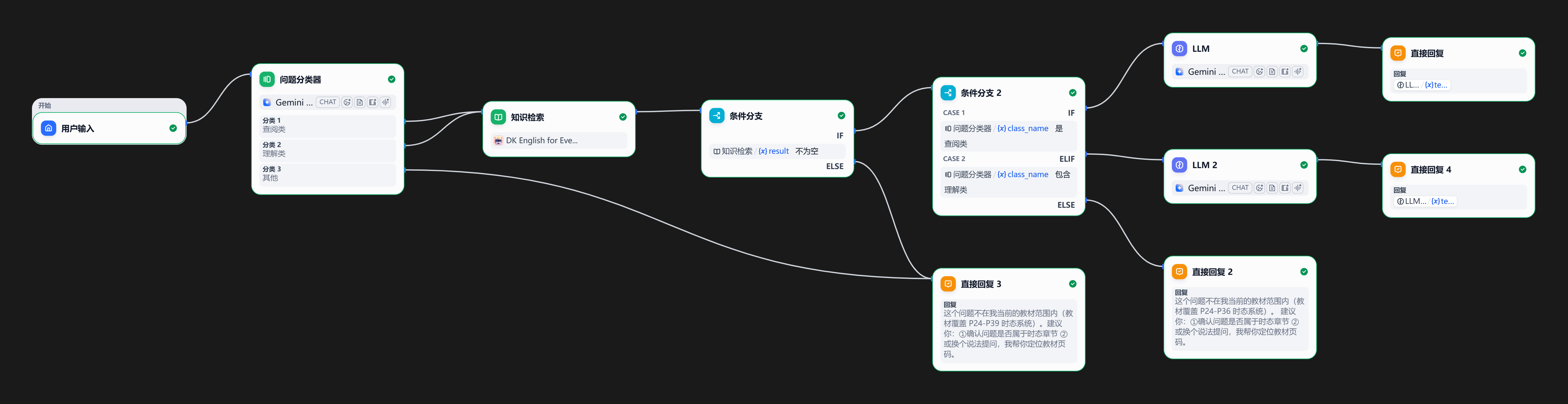
用户输入 → 问题分类器(查阅类 / 理解类 / 其他)→ 知识检索 → 条件分支 → 双 LLM 路径分别回复 + 范围外兜底回复
查阅类:RAG 检索教材 → 直接回答 + [教材Pxx] 页码引用
理解类:不直接给答案 → 引导式回复,保护学习者主动思考
范围外:诚实拒绝 + 给出建议(确认章节 / 换个语法提问)
03 · 真实实例与检索配置回答带页码引用 + 末尾自动声明引用统计

真实问答:每条说明带 [教材P34] 引用,末尾声明"共引用 1 处教材内容,0 处为无来源推断"——幻觉控制做成用户可见的产品功能
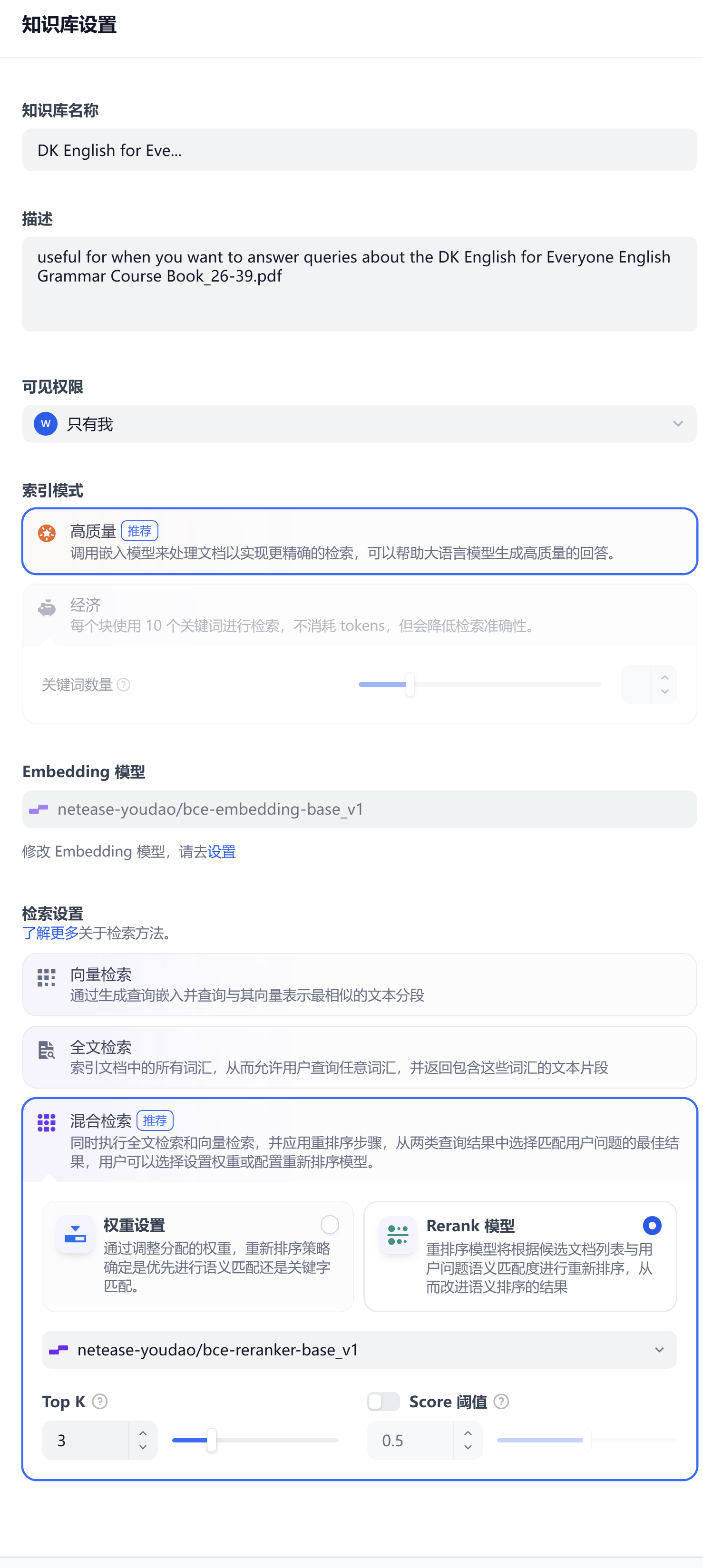
知识库配置:BCE-embedding-base_v1 · 混合检索 + bce-reranker · Top K=3 · Score 0.5 · 高质量索引
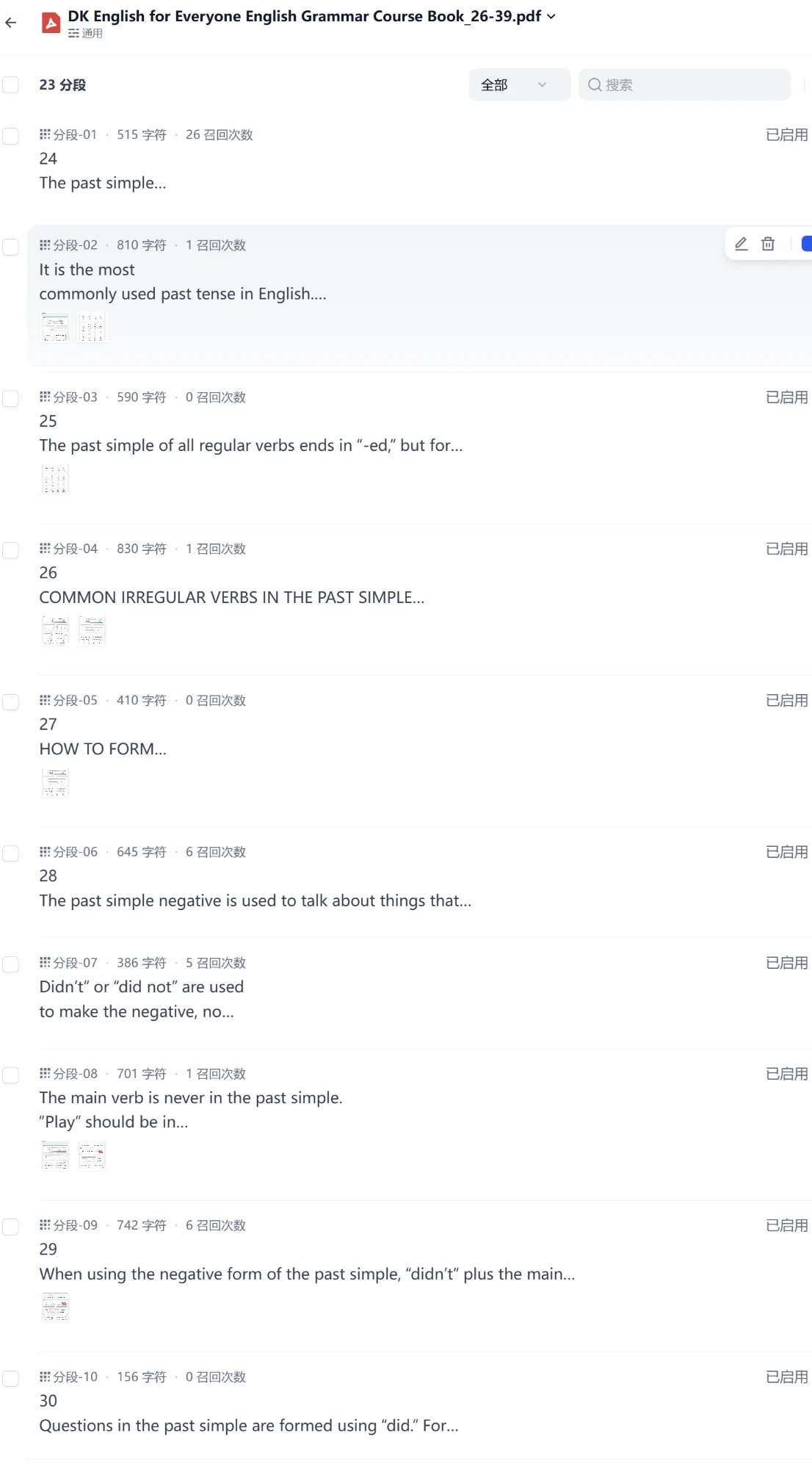
教材知识库 23 个分段,每段记录真实召回次数(26 / 6 / 5 次……)——检索在真实使用中工作的直接证据
每个检索配置为什么这么设(设计意图)
混合检索:向量召回语义相近段落,全文检索兜底术语与精确词——中英混排教材下单一检索易漏
Rerank 重排序:召回后按与问题的相关性重排,保证送入 LLM 的 Top 片段质量
Top K = 3:只取前 3 段,控制上下文长度,减少无关片段诱发幻觉
Score 阈值 0.5:弱相关证据宁可不送——配合"无来源就诚实拒绝"的生成边界
BCE-embedding:BCE vs BGE-large vs Qwen3 对比后选定,中英双语 + 教育适配 + 速度平衡
04 · 评估指标与成果先定义指标,再用 30 题 Golden Dataset 全量实测
| 指标 | 定义 | 目标值 | 实测(Day 2) |
|---|---|---|---|
| 编造率 | 教材无来源却生成内容的题目比例 | ≤ 5% | 0%(0/30) |
| 引用率 | 回答标注教材页码、可核对原文的比例 | ≥ 80% | 90%(27/30) |
| 诚实率 | 超出教材范围时主动拒绝而非硬答的比例 | 100% | 100% |
迭代记录:Day 1 五题预检编造率 100%(5/5 题硬编) → 重写 SYSTEM 提示词为 6 规则约束版(引用标注 · 例句忠实 · 禁止脑补)→ Day 2 全量 30 题复测编造率 0%,11 题超纲问题全部诚实拒绝。
30 题逐题记录节选(前 6 题,完整记录见逐题记录表 CSV)
| # | 问题 | 表现 |
|---|---|---|
| 1 | 规则动词过去式怎么构成?有哪些拼写变化? | 回答"加 -ed" [教材P24];拼写变化教材未提供 → 诚实说无法回答(部分回答+部分拒绝) |
| 2 | 现在完成时的结构是什么?have 和 has 怎么用? | have/has + 过去分词 [教材P34];Has 用于 he/she/it [教材P34] |
| 3 | 过去进行时和过去简单时有什么区别? | 持续性 vs 一次性 [教材P24, P32] |
| 5 | 为什么过去式否定句用 didn't + 动词原形? | 给出构成方式 [教材P28-29];对"为什么"诚实说无法回答 |
| 6 | 动词 go 的过去式是什么? | 根据 P36 例句回答 went [教材P36] |
| 7 | 动词 eat 的过去式是什么? | 教材未提及 → "这个问题不在我的教材范围内,我无法回答" |
模式总结:所有"为什么""怎么形成"类问题教材均未覆盖——这是教材覆盖边界而非 RAG 缺陷。v1.1 的问题分类器(查阅/理解/范围外三分流)正源于此发现。
05 · 反思这个项目教会我什么
评估先于功能:先建质量基线(地基稳固),再叠加引导式教学等模式——顺序反了就是在沙地上盖楼
幻觉控制可以产品化:引用统计声明不是内部指标,是用户随时能核对的功能
"部分回答 + 部分拒绝"比全答更符合教育产品哲学——有来源的答,无来源的明确说无法回答