PROJECT 02 · AI AGENT
WordCraft 词义理解 Agent —— 从 PRD 到封账交付的完整闭环
成人英语词义理解 Agent MVP · AI 产品经理 · 2026.03-2026.0601 · 定位与 PRD 核心用户定义 · 范围裁剪 · 北极星 · 质量分级(真实摘录)
痛点 —— 查词的真问题不是"查不到"
① 释义太多:一个词 8-12 条释义,不知道先学哪个② 例句太难:例句比单词本身还难,看不懂用法
③ 看完仍不会用:真实句子里认不出是哪个意思
方案 —— 受控词义理解 Agent
先给 3 条最值得学的释义卡片(减负),支持句中语境判断(运用)。为什么要"受控":LLM 直接解释可能编造义项 → 义项只从词库 raw_definition 中选择、不自造,可追溯可评估。单词句中目标词消歧英语 / AI 术语
核心用户定义(PRD 原文):"有一定英语基础,但经常被多义词卡住的学习者。核心问题不是查不到释义,而是释义太多、例句太难、看完仍不会用。"不做零基础用户、不做词典重度研究型用户。
北极星指标:单词从"见过"到"能用"的转化率,拆 3 个代理指标——查词完成率 / 释义复述率(24h 后能否复述核心义)/ 造句正确率。
MVP 范围裁剪:自由造句练习 + AI 评判反馈主动降级进 V2 Backlog,保留更易验收的"句子-释义匹配"——裁剪有记录、有理由。
quality_flag 质量分级:义项低频、过时或无法生成自然现代表达时标记 low_confidence——允许空例句但必须给 card_notes,用户侧提示"该释义较低频,暂不推荐优先练习"。数据不够时诚实降级,不硬编例句。
三条 User Story 对应三个痛点(真实摘录)+ AC 验收标准
US1(P0)As a 英语学习者,I want to 输入目标单词后优先看到 3 条最值得先学的核心释义卡片,So that 我不用被传统词典的 8-12 条释义淹没。
US2(P0)As a 想真正学会一个词的英语学习者,I want to 点击某条核心释义后看到简单解释、低难度例句和常见搭配,So that 我不只是知道中文翻译,而是知道这个意思通常怎么用。
US3(P0)As a 在真实句子里遇到多义词的英语学习者,I want to 输入句子和目标单词、让系统判断对应哪条释义并给出依据,So that 我能把释义和真实语境连接起来,避免"看懂词典却看不懂句子"。
AC = 验收标准,把每条 US 翻译成可判定的测试条件。如 AC1.1:Given 查词入口页 / When 输入有效单词提交 / Then 必须返回 3 条卡片、默认不展示第 4 条;Failure:少于 3 条且无说明 / 超过 3 条 / 空结果;Test Type 含 LLM-as-Judge 与 Human Review。
02 · 从原型到工作流先设计(Figma 原型),后构建(Dify Agentic Workflow)

五页低保真原型:查词入口 → Top 3 释义卡 → 义项展开 → 句子-释义匹配 → 学习历史(点击放大)
低保真原型交互演示(51 秒)

真实 Dify Agentic Workflow:任务类型判断 → 任务边界判断(Guardrail)→ 条件分支 → 词库查询 → 释义筛选 → 格式清洗 → 学习卡片生成 / 澄清回复
为什么拆成多节点:Spike 实测单节点一次生成三卡时,money / problem 多次触发 MAX_TOKENS 输出截断 → 拆为「释义筛选 → 格式清洗 → 卡片生成」各司其职,输出可稳定 JSON 解析。
03 · 产品 Demo六个真实输出场景(左右切换,点击放大)
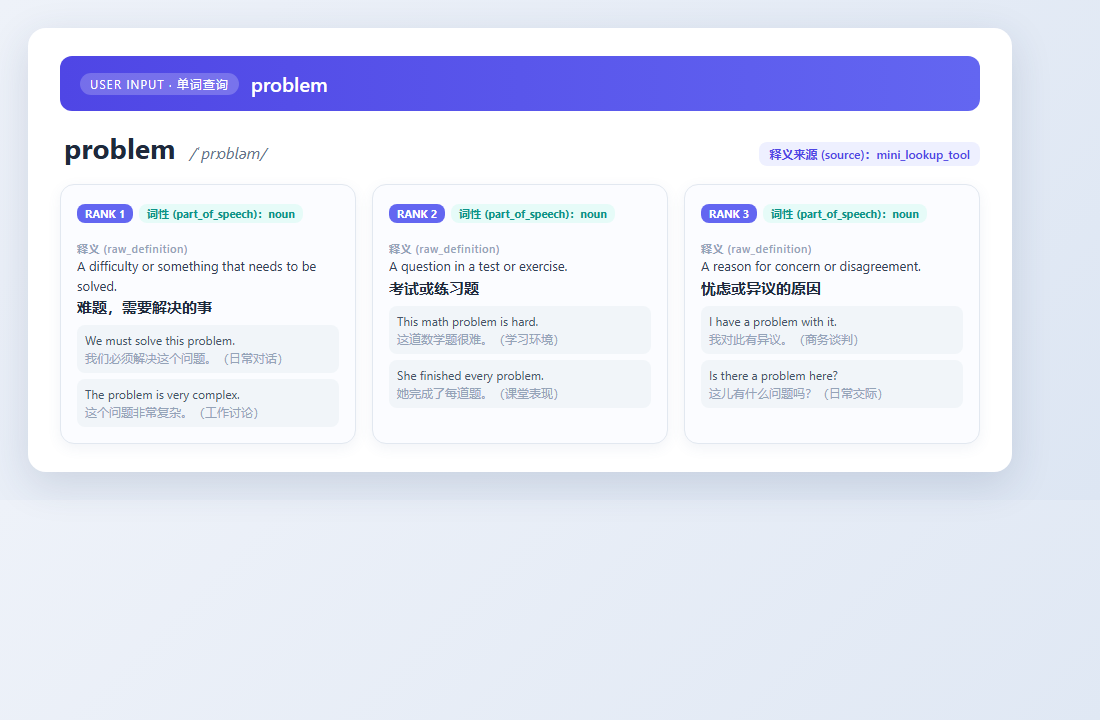
① 单词查询:problem → Top 3 释义卡片,每张可追溯 raw_definition
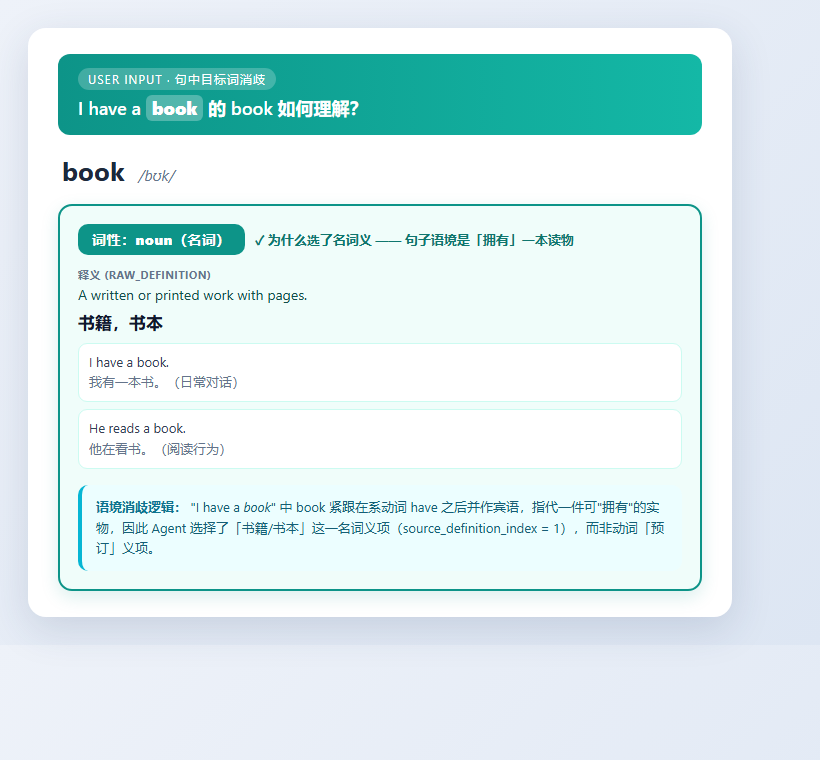
② 语境消歧:"I have a book" → Agent 选名词「书」
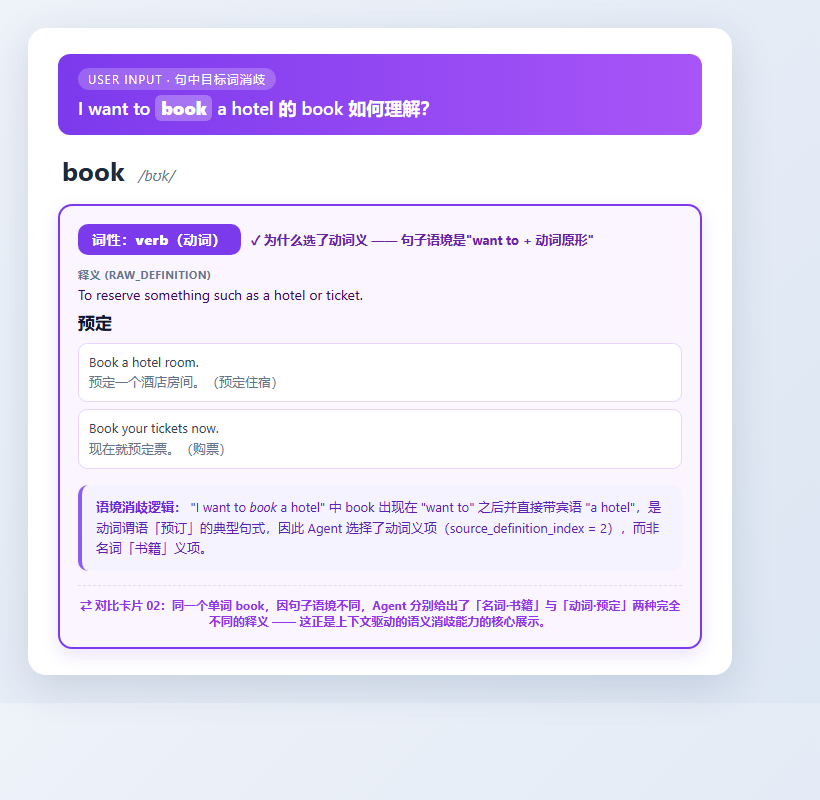
③ 语境消歧:"I want to book a hotel" → 同一个词选动词「预订」,并解释判断依据
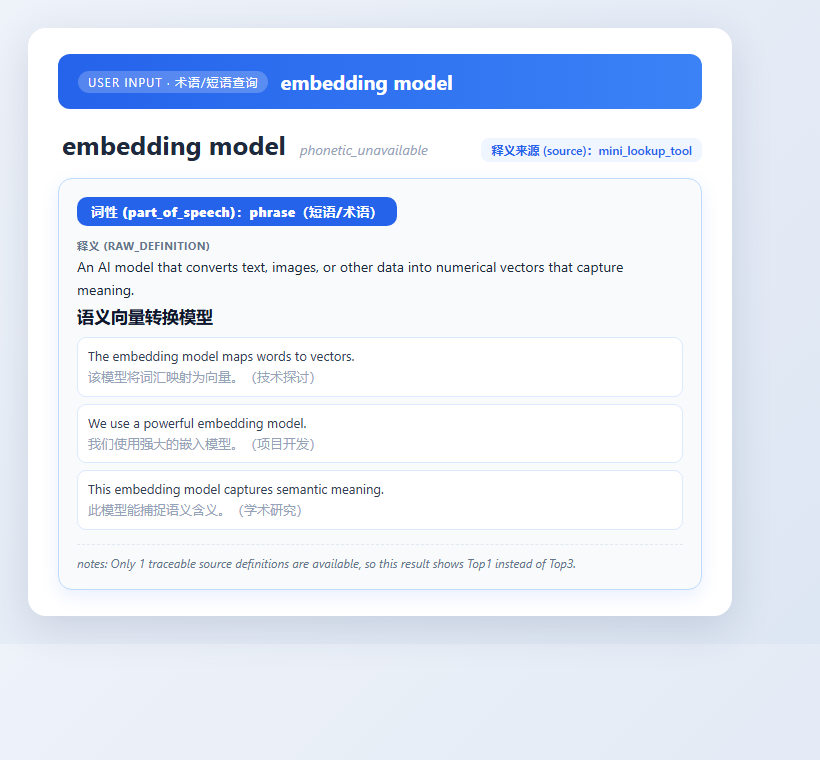
④ 术语短语:embedding model → 单张术语卡,不拆词解释
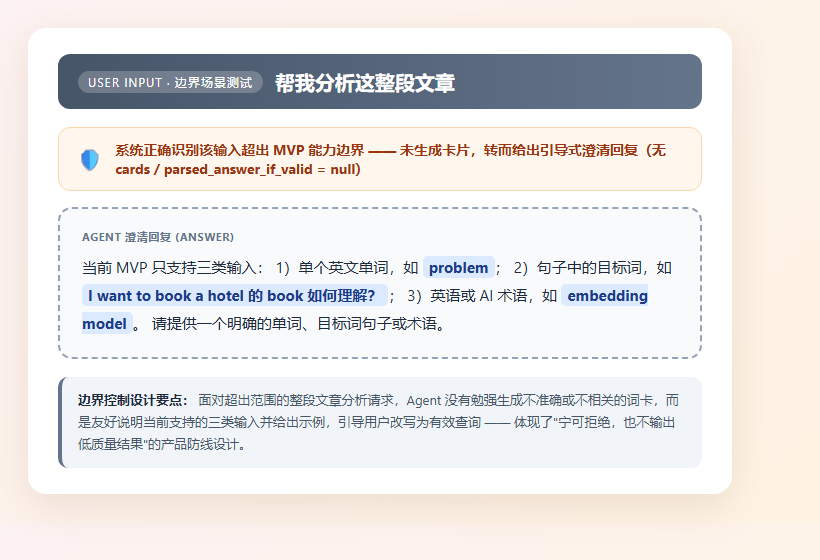
⑤ 边界拦截:不支持的输入被 Guardrail 拦截,返回友好澄清而非报错

⑥ Baseline 测试汇总:15/15 全通过
04 · 模型选型与 Token 经济4 模型同一套 Prompt 实测 · 单价由调用日志反推
选型问的不是"哪个最好",而是"怎么分工最优"。机会评估阶段要回答 4 个问题:哪个能稳定产出结构化 JSON?成本/延迟/质量怎么平衡?哪个适合主流程、草稿、Bad Case 重跑?有无爆 token 等生产化风险?
| 模型 | 成本 / 词 | 平均延迟 | 质量 | 路由角色 |
|---|---|---|---|---|
| Gemini 2.5 Flash | $0.00124 | 3.58s | 中高:JSON 稳定、语义例句均衡 | 主流程 |
| Gemini 2.5 Flash Lite | $0.00026 | 5.99s | 中低:释义浅、例句生硬,返工率高 | 草稿批量 |
| Gemini 3 Flash Preview | $0.00500 | 9.59s | 高:语义最好但成本 4 倍 | Bad Case 重跑 |
| Gemini 3.1 Flash Lite Preview | 不稳定 | 13.85s | acute/sound 爆 11k+ token | 不采用 |
最便宜 ≠ 总成本最低:Lite 单价仅 1/5,但质量不达标导致返工,综合成本反超
测试口径要干净:剔除 Dify 对话记忆带来的上下文污染样本后才计算平均成本;异常值给含 / 排除两种口径
05 · 测试与成果分层验证,先通路后规模 —— 15 样本 Baseline 15/15
能力一:分层测试策略(冒烟 → 哨兵 → 基线)能力二:Bad Case 归因 → 修复 → 验证闭环
测试链:冒烟测试 4/5(5 样本低成本验通路)→ 根因定位(Guardrail 失败后穿透到生成节点)→ 修复 + 单样本验证(新增澄清分支)→ 复测 5/5(重跑原集合防回归)→ canary 哨兵(money 词条单点复测)→ Baseline 15/15 封账交付。全程 Python 批测脚本执行,JSONL 原始结果与 CSV 运行日志留存,可复现。
| 指标 | 结果 | 为什么看它 |
|---|---|---|
| 总通过率(word 8 + sentence_word 5 + phrase 2) | 15/15 · 100% | 端到端链路健康度 |
| 句中词义消歧通过率 | 5/5 · 100% | 核心差异化能力(语境判断)是否成立 |
| 义项 raw_definition 可追溯率 | 8/8 · 100% | 幻觉控制的根基:卡片不是模型编的 |
| 回答 JSON 合法率 | 15/15 · 100% | 可程序化批测与前端集成的前提 |
同一目标词在不同句子选出不同义项(book=书/预订,school=学校/鱼群),证明 Agent 在利用句子语境消歧,而非按词表顺序机械选择。
06 · 反思
词库部分词条只有 2 条 definitions 时不强行补第 3 张卡——数据有多少说多少,与幻觉控制一脉相承
wordnet_fallback 来源正确标记风险而非隐藏,为 Bad Case 分类预留抓手
模型选型的结论是可解释的路由策略,而不是一个"最好的模型"——成本思维是 AI PM 的必修课