PROJECT 03 · AI 效率工具
润言 —— 语音直出可用文字的端到端交付
个人项目 · 从 0 到 1 独立交付 Windows 客户端 · 2026.06-至今01 · 项目定位与工作流四段式流水线 · 转写层双引擎可切换
痛点
自媒体博主、文案写手用传统语音输入时"只转字、不可用":口水词、断句混乱、中英识别失真全留给用户手改——省下打字时间、赔进修改时间。方案
四段式流水线让语音内容直出可用文字:热键说话,AI 转写后由 LLM 自动清洗口水词、补标点、保留原意,直接输入到光标位置。交付
从功能原型到含系统托盘、热键触发、使用统计的完整 Windows 可分发客户端,24 轮真实使用驱动迭代。PythonGroq WhisperSenseVoiceGemini / DeepSeekPrompt 工程

四段式架构与双引擎决策全景(点击放大)
02 · 产品演示真实使用录屏 + 润色效果
端到端使用演示:按热键说话 → 转写清洗 → 自动输入到目标窗口
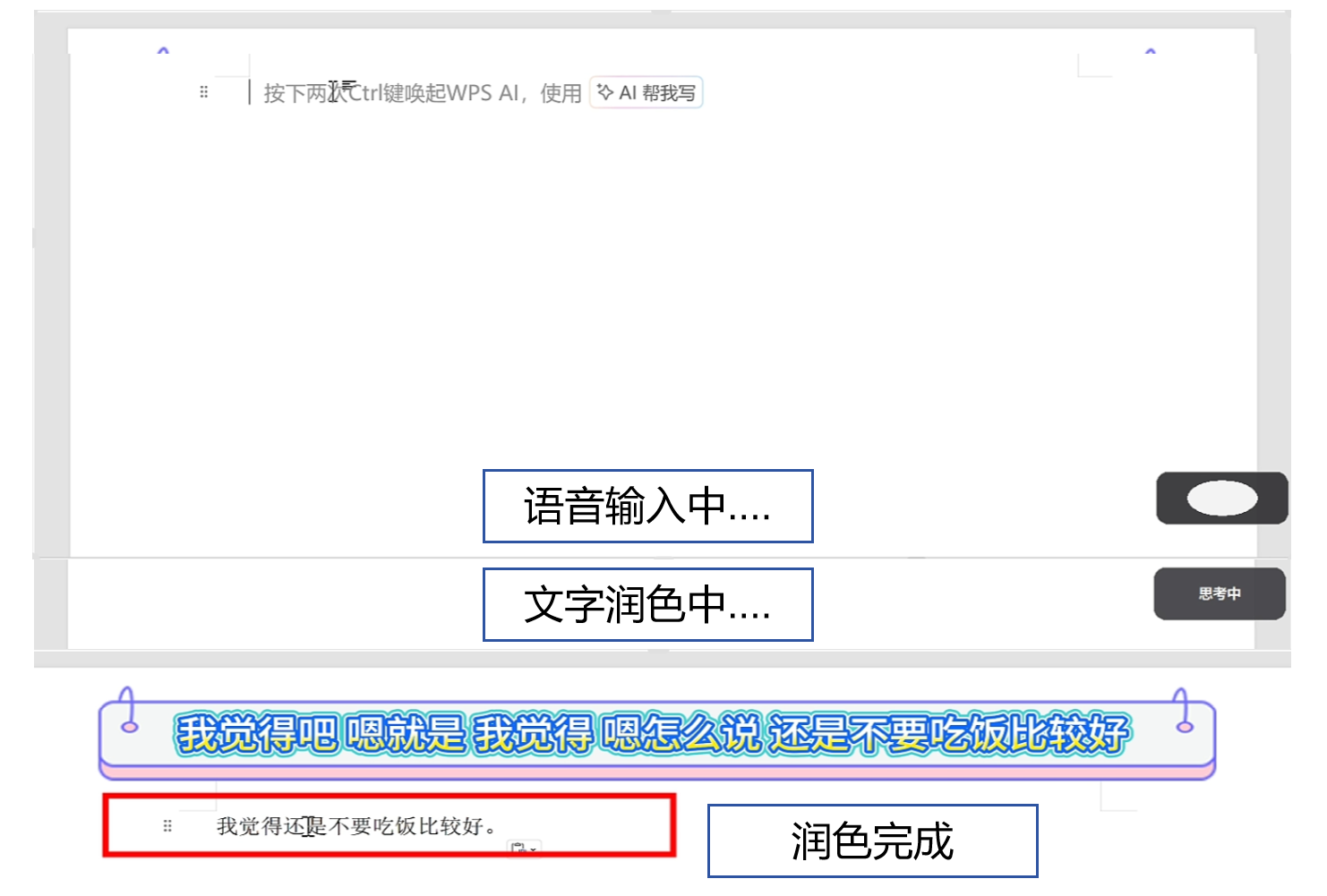
真实润色:口语"我觉得吧 嗯就是 我觉得 嗯怎么说 还是不要吃饭比较好" → 输出"我觉得还是不要吃饭比较好。"

悬浮胶囊状态指示(录音 / 处理动画)
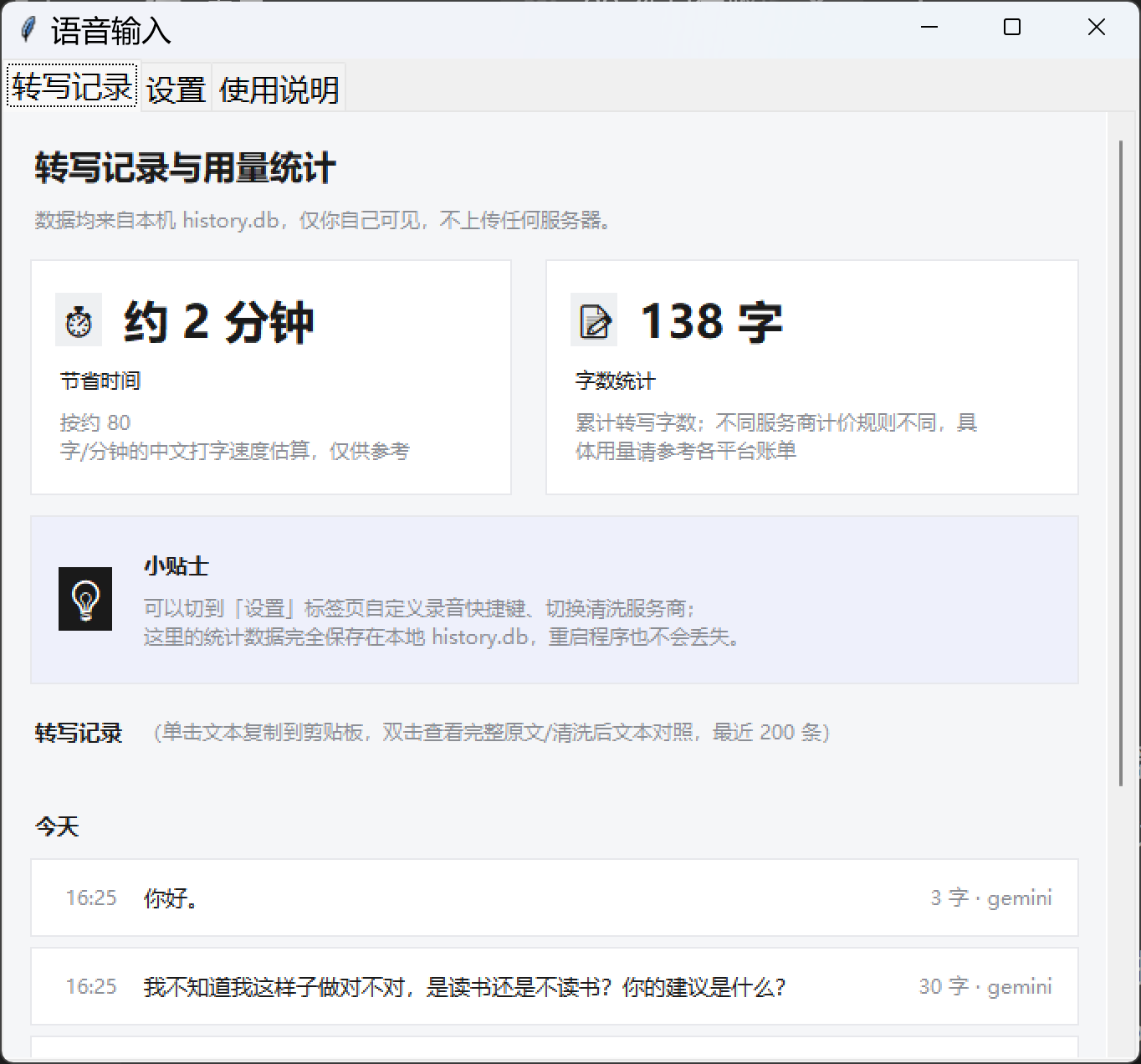
转写记录与用量统计:按打字速度折算"节省时间";数据仅存本机
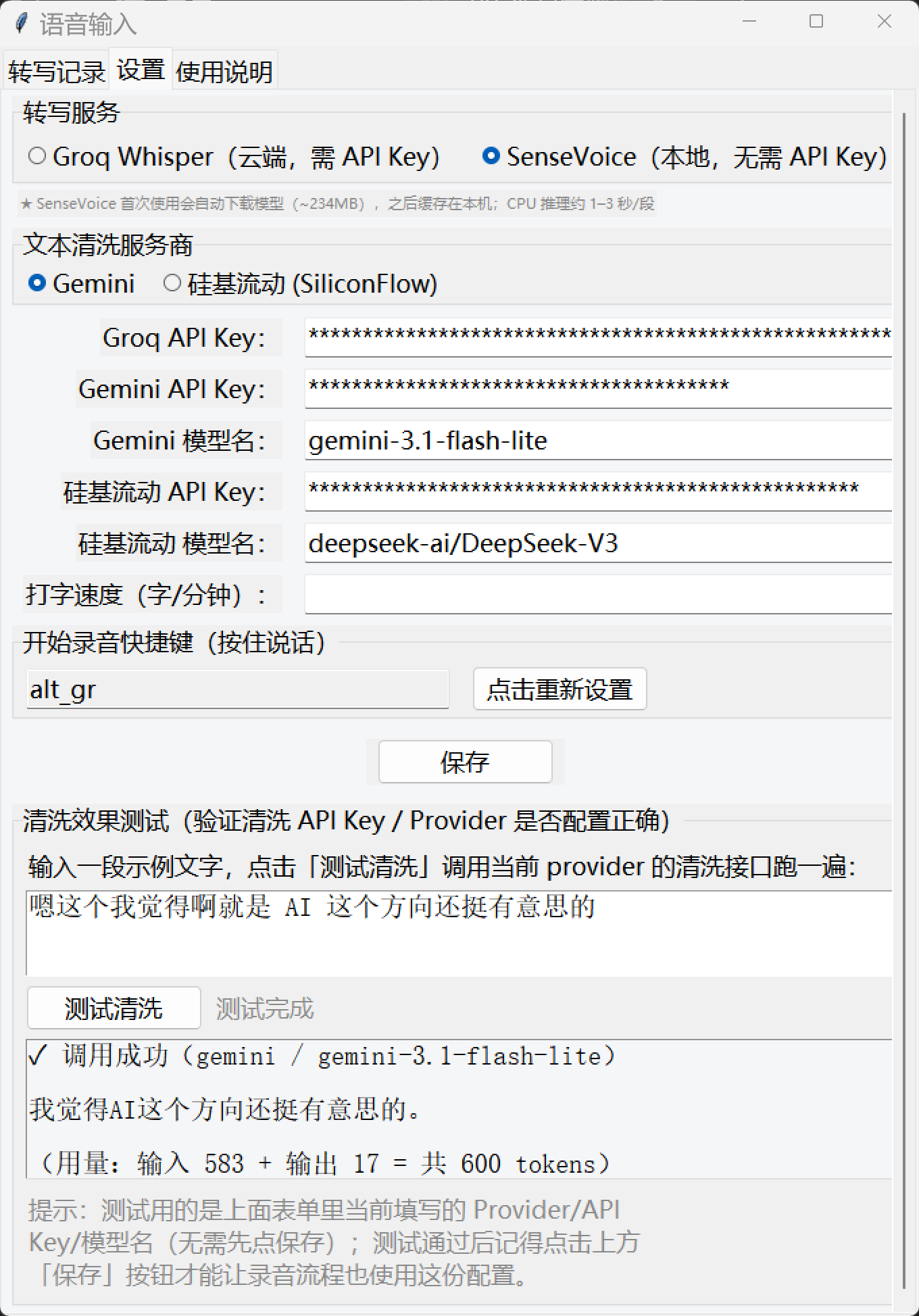
设置页:双引擎切换、热键自定义、内置"测试清洗"自检面板

系统托盘常驻
03 · 关键架构决策为什么做双引擎 —— 调参不解决就换架构,每一步有证据
第一步 · 发现问题
中英混说场景转写乱码:英文主导时后续中文被整句翻译成英文
中英混说场景转写乱码:英文主导时后续中文被整句翻译成英文
第二步 · 穷尽低成本手段
4 轮 prompt / language 参数调优,全部无效
4 轮 prompt / language 参数调优,全部无效
第三步 · 调研定根因,换架构
确认 Whisper 架构不支持 code-switching、无参数可修复 → 接入 SenseVoice 本地引擎
确认 Whisper 架构不支持 code-switching、无参数可修复 → 接入 SenseVoice 本地引擎
结论:形成"云端快(Groq whisper-large-v3)、本地稳(SenseVoice,离线 + 中英混说稳定)"的双引擎可切换架构,用户按场景自选。
04 · 24 轮迭代闭环发现 → 归因 → 修复 → 验证,Bad Case 沉淀为产品规则
| 阶段 | 轮次 | 主线 |
|---|---|---|
| 产品 / UX 塑形 | 1-7 | 按住说话改造 → 热键修复 → 转写记录与用量统计 → 胶囊动画 UI → 托盘常驻 → 主窗口三合一 |
| 联调与打包 | 8-10 | 白盒自测脚本(16 项全 PASS)→ 重新打包验收 → Whisper prompt 调优 |
| 核心技术攻坚 | 11-14 | 中英混杂乱码 4 轮调参 → 调研确认 Whisper 架构限制 → 接入 SenseVoice 形成双引擎 |
| 分发工程化 | 15-20 | 含 SenseVoice 可分发打包 → 定名「润言」→ 目录结构清理 |
| 打磨验收 | 21-24 | 统计可配置 → 界面修复 → 第 24 轮修复"疑问句被实质性回答"幻觉(55 字问句 → 331 字建议) |
清洗层幻觉类型从 2 类扩到 3 类(对话式回复 / 中文过度删除 / 疑问句被实质回答),每个 Bad Case 都沉淀为新的 Prompt 约束——产品边界随真实使用持续校准。
05 · 测试逻辑与方法回归测试集沉淀 + 脚本化
回归测试集沉淀:每次出现 Bad Case,把出错的那条输入固化为回归用例——test_clean_prompt.py 6 个回归用例(历史失败形态全量固化),每次改 Prompt 调真实 API 跑全量,6/6 PASS 才算修复完成,杜绝"修一个坏一个"。
Python 白盒自测:16 项检查全 PASS,不依赖真实麦克风与网络,可重复执行
真机验收循环:以自身为种子用户,每轮"打包 → 真机验收 → 修复 → 再打包"
24 轮真实使用迭代Windows 可分发客户端数据 100% 本地化
06 · 反思
产品先于文档:PRD 为事后沉淀,下次应在迭代中同步留痕(已用全程会话记录弥补可追溯性)
Whisper 的架构缺陷如果在选型阶段做中英混说压测即可提前发现——转写引擎选型测试集应覆盖目标用户的真实语料分布